Reproducible Code & Coffee: Three perspectives on making research workflows reproducible
As part of the GhentCORR “& Coffee” series, we recently hosted a Reproducible Code & Coffee session. The goal was simple: bring researchers together and openly discuss how we can make research code and analyses easier to understand, reuse, and trust. Many research results today depend on code: data cleaning scripts, data analysis pipelines, simulations, or tailored software tools. Yet code is rarely treated as a first-class research output.
Over coffee, three speakers from different research contexts shared their experiences with reproducibility in practice and reflected honestly on what works, what challenges they encounter, and what still needs improvement.
Perspective 1: Publish the workflow, not just the paper (Toon Verstraelen)
Toon Verstraelen (Center for Molecular Modeling) opened the session by questioning how current publication practices can fall short when it comes to research integrity. As it becomes easier to automatically generate papers, the final manuscript alone is no longer sufficient evidence of careful and honest research. If only the polished end result is visible, it is difficult for others to judge how that result was actually obtained.
While researchers often share their data (for example via repositories such as Zenodo), Toon argued that data alone is often not actionable and reusing it typically requires reconstructing the original analysis decisions — often by guesswork.
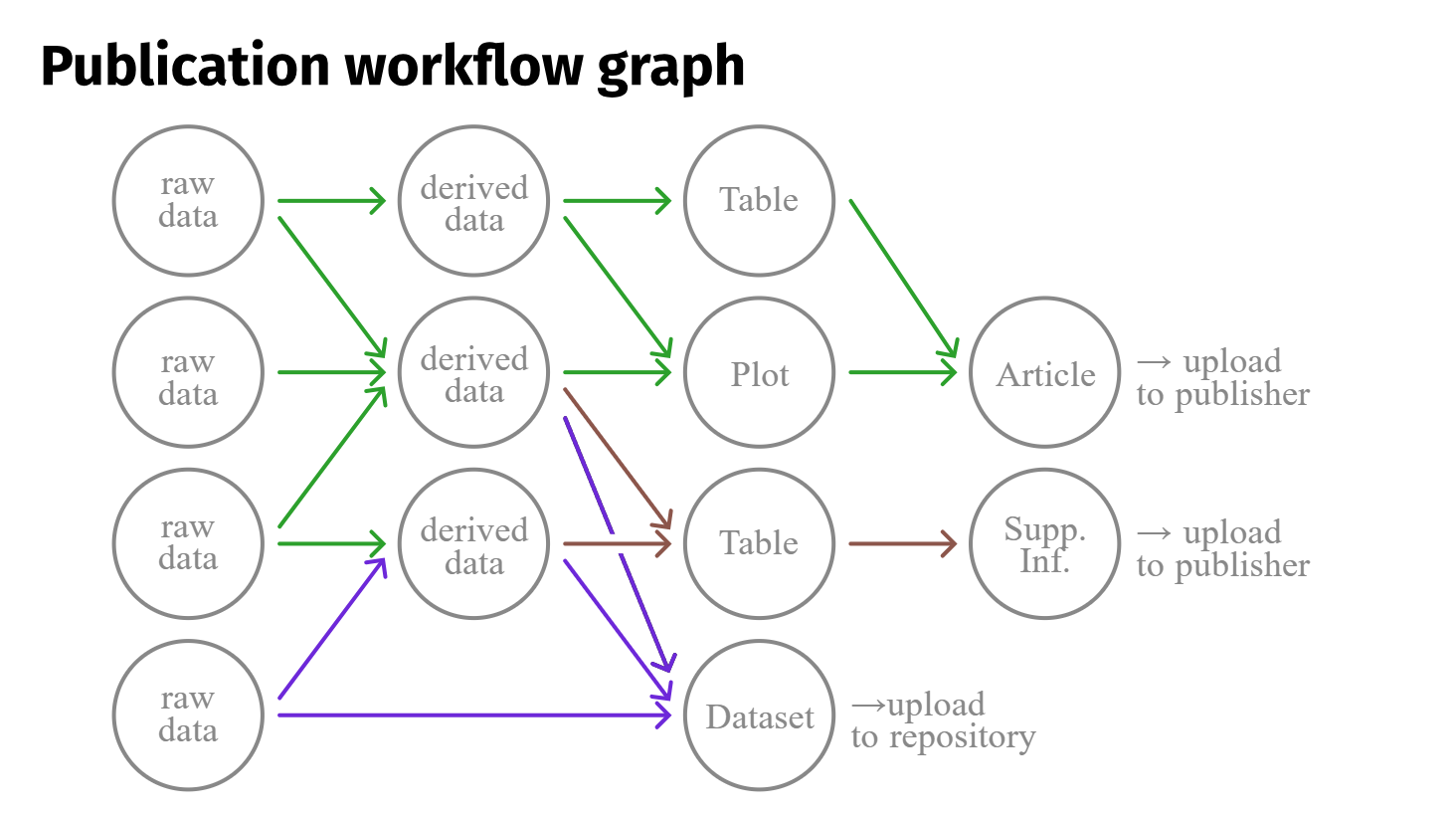
Instead, he proposed shifting attention from outputs to processes by introducing the concept of a publication workflow: the full chain of steps that connects raw data to figures and text in a paper. This includes data processing, parameter choices, intermediate results, and scripts — what he described as “the arrows between the dots”. Making these steps visible helps errors surface earlier and allows credit to be given to the full research process, not just the final article.
Multiple tools can be used to document and automate research workflows, and Toon presented a comparison between workflow tools and build tools, each with their own strengths and trade-offs. Ideally, both flexibility and efficiency are needed: dynamic workflows that can adapt to changes, combined with incremental execution (only rerunning what has changed). To explore this, Toon developed his own tool, StepUp, which aims to combine both aspects.
In practice, researchers also rely on containers to package software environments so analyses can be rerun on another machine. While these approaches already support reproducibility in meaningful ways, the discussion also touched on how challenging it is to ensure results remain reproducible over very long timeframes, given the continuous evolution of software and hardware environments.
The key message was therefore not “use this one perfect tool”, but rather: make the workflow visible, and treat it as a genuine research output alongside the paper itself.
Perspective 2: Treat research code like real software (Sander Hendrickx)
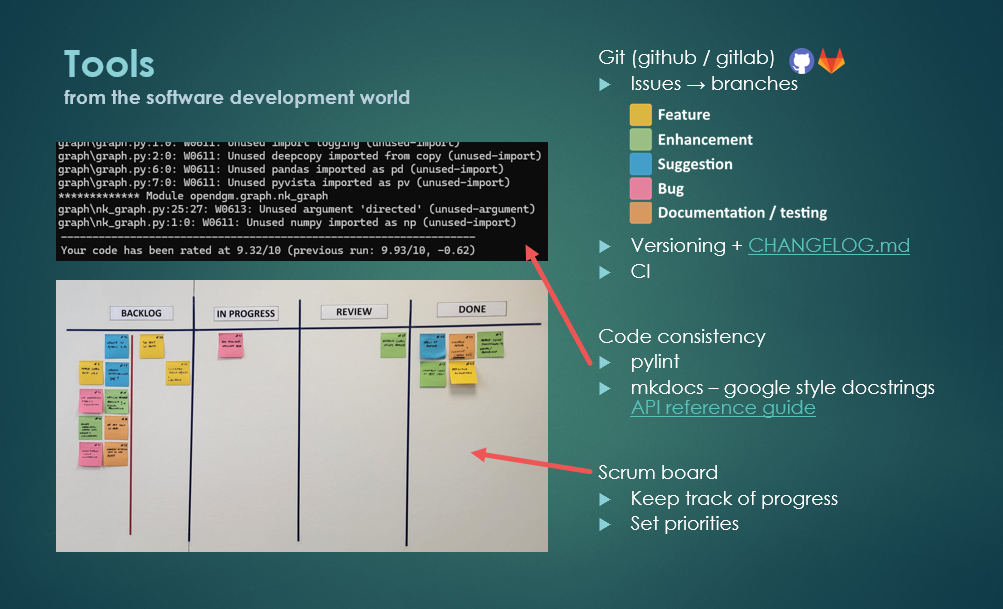
Sander Hendrickx shifted the focus from publications to day to day research practice. Based on his experience in the Biophysics research group, he showed how quickly code can become unmanageable if it is not structured properly (see slides).
Early on, his group worked with a single large code repository shared by many people. While convenient at first, this quickly led to conflicts, broken functionality, and confusion about who was responsible for what.
To address this, the group moved towards a clean separation between infrastructure and research. They developed a well-maintained framework (OpenDGM), while keeping individual research projects in separate repositories that build on that framework. This way, exploratory work does not disrupt the core codebase, and useful features can later be integrated in a more controlled way.
Sander emphasised that many of the challenges researchers face are not unique: they have already been tackled in software engineering. By adopting practices such as version control, clear documentation, issue tracking, continuous integration, and automated testing, research code becomes not only more reproducible but also easier to maintain and extend.
At the same time, he stressed that the biggest challenges are rarely technical. Designing a clear code structure is difficult, especially for researchers without a software background, and sharing code requires a real shift in mindset. Without agreed standards and some level of responsibility within the group, code quality can quickly deteriorate.
Despite these challenges, the benefits are clear. A shared and well-maintained framework allows researchers to build on each other’s work, leading to more robust and reproducible research over time.
Perspective 3: Convenient today, reproducible next year? (Bart Mesuere)
Bart Mesuere shared his lessons learned from more than a decade of work on Unipept, a research tool that began as a web application (see slides). His story highlighted a familiar tension in research software: what is convenient for users today is not always easy to reproduce tomorrow.
From the outset, the choice for a web application made perfect sense. It lowered the barrier for use, required no installation, and allowed a single maintained version of the software to be shared with a wide audience. For researchers without a technical background, this accessibility was a major strength.
However, as the tool evolved, the limits of this approach gradually became clear. Over time, both the software itself and the underlying biological databases (such as UniProt) were updated regularly. As a result, the same input data could produce different outputs depending on when the analysis was run.
Bart described how the team took incremental steps to deal with reproducibility by improving transparency. They began by clearly indicating which software and database versions were used in each analysis, and by maintaining a public changelog documenting what had changed to the web application over time. In this context, reproducibility became less about freezing the entire system, and more about making changes visible and understandable. Besides, they decided to open up the source code, allowing others — at least in principle — to run previous versions themselves. Although there were initial concerns about others reusing or “stealing” ideas, these fears did not materialise in practice.
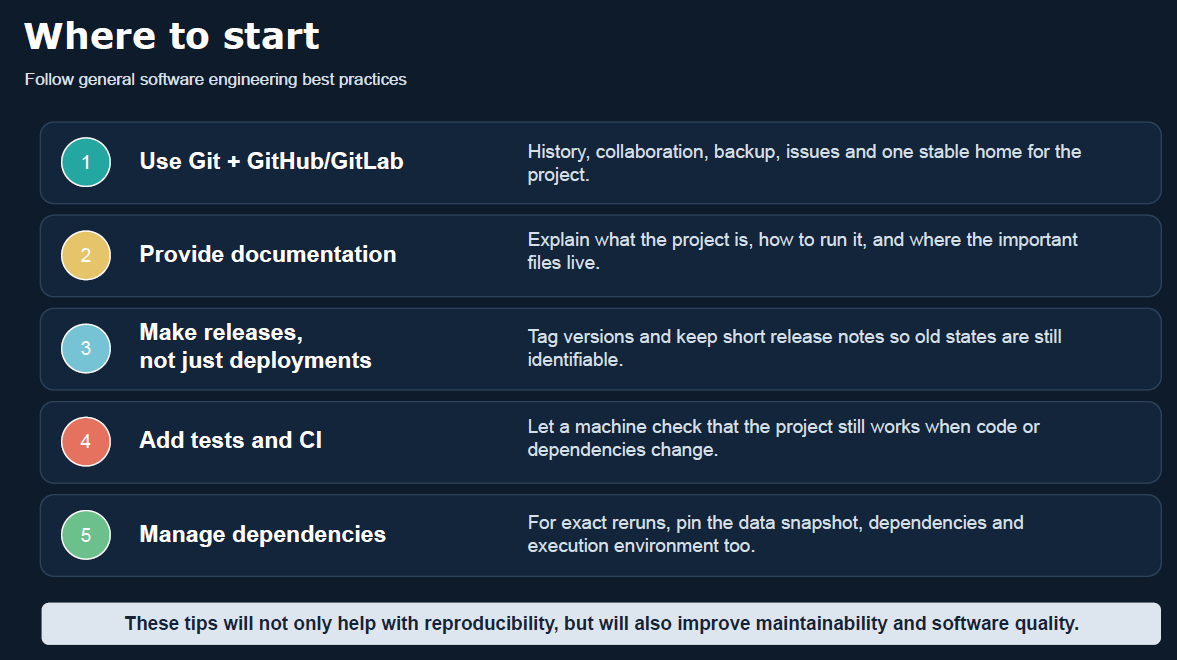
Bart showed that there is often no perfect solution, but reproducibility can be improved step by step. Importantly, many of the practices that support reproducibility — such as clear documentation, explicit dependencies, versioned releases, and testing — also make research software easier to maintain, share, and build upon over time.
Common threads
Across the three talks and the discussion with the audience, several themes came back repeatedly:
- Reproducibility is about process, not perfection
- Making work visible invites critique, but also improvement
- Technical tools help, but incentives, training, and culture matter as well
- Small, concrete steps already make a big difference
The Reproducible Code & Coffee session showed that reproducibility is not an abstract ideal reserved for experts. It is something researchers can gradually build into their everyday practice — preferably with good coffee and open conversations.
References and acknowledgements
This blog post was written by the GhentCORR core team. Copilot was used for editorial support, including improving clarity, flow, and consistency of the text.
Enjoy Reading This Article?
Here are some more articles you might like to read next: