The reproducibility crisis in science: what’s going wrong and how to fix it
Scientific research rests on a simple but powerful idea: if a study is sound, others should be able to reproduce its results. Yet across many disciplines, this expectation is unmet.
In a recent webinar (see slides) organised by GhentCORR, Thomas Guillemaud and Denis Bourguet — cofounders of Peer Community In (PCI) — unpacked why reproducibility has become such a widespread concern, and how relatively straightforward changes in research practice could make a substantial difference.
Why so many published results look “too good to be true”
A striking feature of the scientific literature is how rarely studies report negative or null results. Metaresearch has shown that between 80% and 95% of published papers have positive findings, with particularly high rates in disciplines such as psychology and biomedical research (Fanelli, 2010; Allen et al., 2019; Scheel et al., 2021). At first glance, this might seem reassuring. Statistically, however, it is unexpected.
This is because a large and growing body of evidence shows that the statistical power of many studies is very low. Statistical power — the probability that a study will detect a real effect if it exists — depends mainly on sample size, variability of the phenomena, and true effect size. Surveys and meta-analyses across fields — including neuroscience, ecology, evolutionary biology and medicine — consistently report low power values, often below 20–30% (Jennions & Møller, 2003; Button et al., 2013; Lamberink et al., 2018; Yang et al., 2023).
Low statistical power has consequences that are often underestimated. While it is well known that underpowered studies are unlikely to detect true effects, it is less widely appreciated that low power also increases the probability that statistically significant results are false positives (Button et al., 2013).
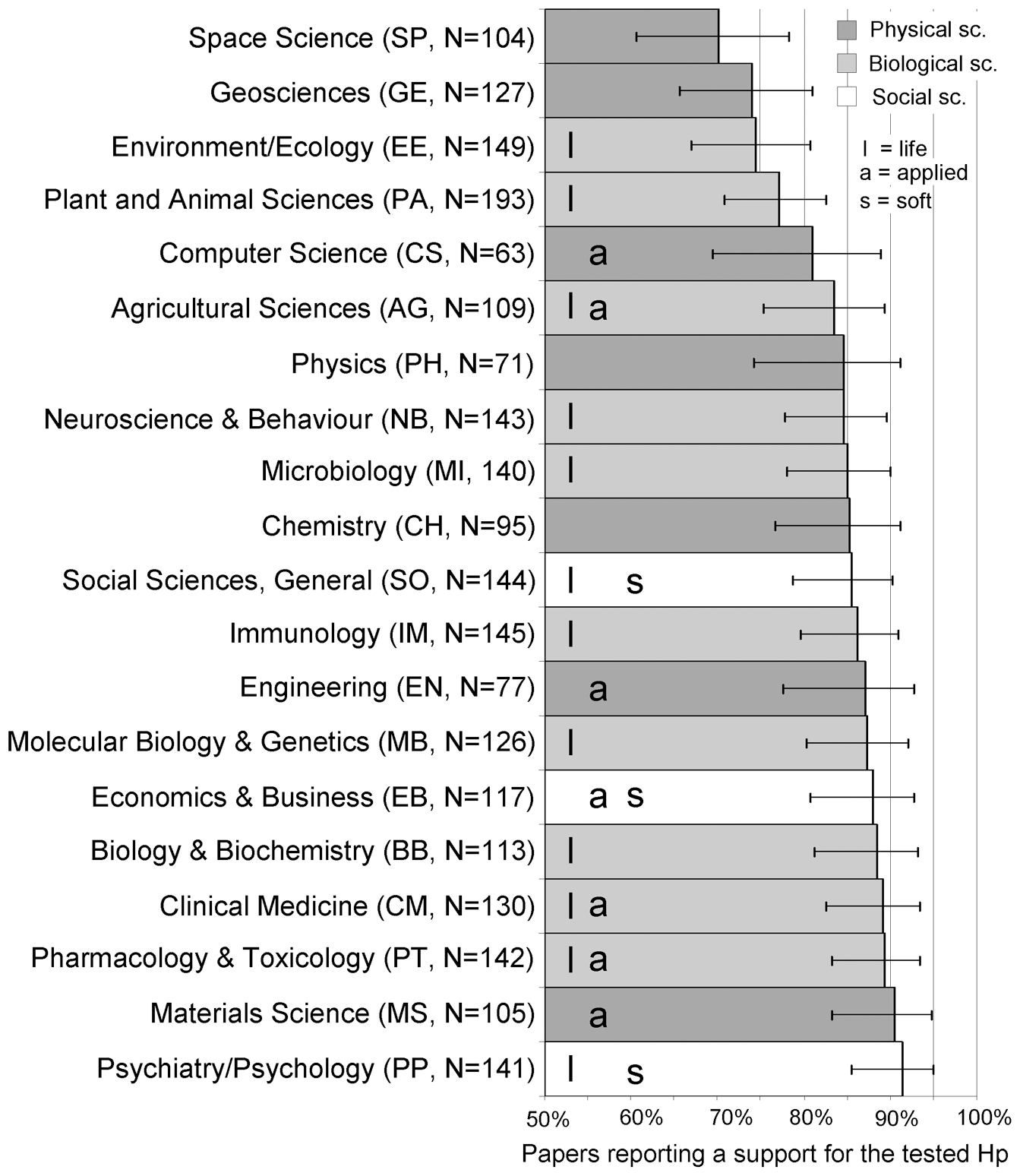
Figure 1. Percentage of papers with positive results by discipline, from Fanelli (2010).
Together, these factors create a paradox at the heart of the reproducibility crisis: the literature is dominated by positive results, even though the majority of studies are too underpowered to produce reliable ones. When low statistical power is combined with bias, selective reporting, and analytical flexibility, most claimed research findings are more likely to be false than true (Ioannidis, 2005).
But, is it a crisis?
Scepticism about the term crisis is understandable. Variation and occasional failures to replicate have always been part of scientific progress. However, the scale and consistency of recent evidence suggest that the situation goes beyond isolated problems.
Although with some variability in outcomes, large-scale replication efforts across life sciences and pre-clinical studies consistently show very low reproducible rates overall, with estimates ranging from only 10–25% of studies or effects reproducing robustly, many findings reproducing only partially, and a majority failing to reproduce altogether (Begley & Ellis, 2012; Ioannidis et al., 2009; The Reproducibility Project: Cancer Biology, 2014). In the behavioural sciences, more recent evidence from Nature’s 2026 reproducibility special issue paints a similarly concerning picture: a years‑long, multi‑team meta‑research effort found that only about half of published claims could be successfully replicated.
This problem is not new. Warnings about the trustworthiness of research findings were already being raised in the 1990s. What is relatively recent is the willingness to openly frame the situation as a crisis. That shift in language has proven especially effective in psychology where, naming and confronting the problem has already improved reporting standard and statistical power in published studies.
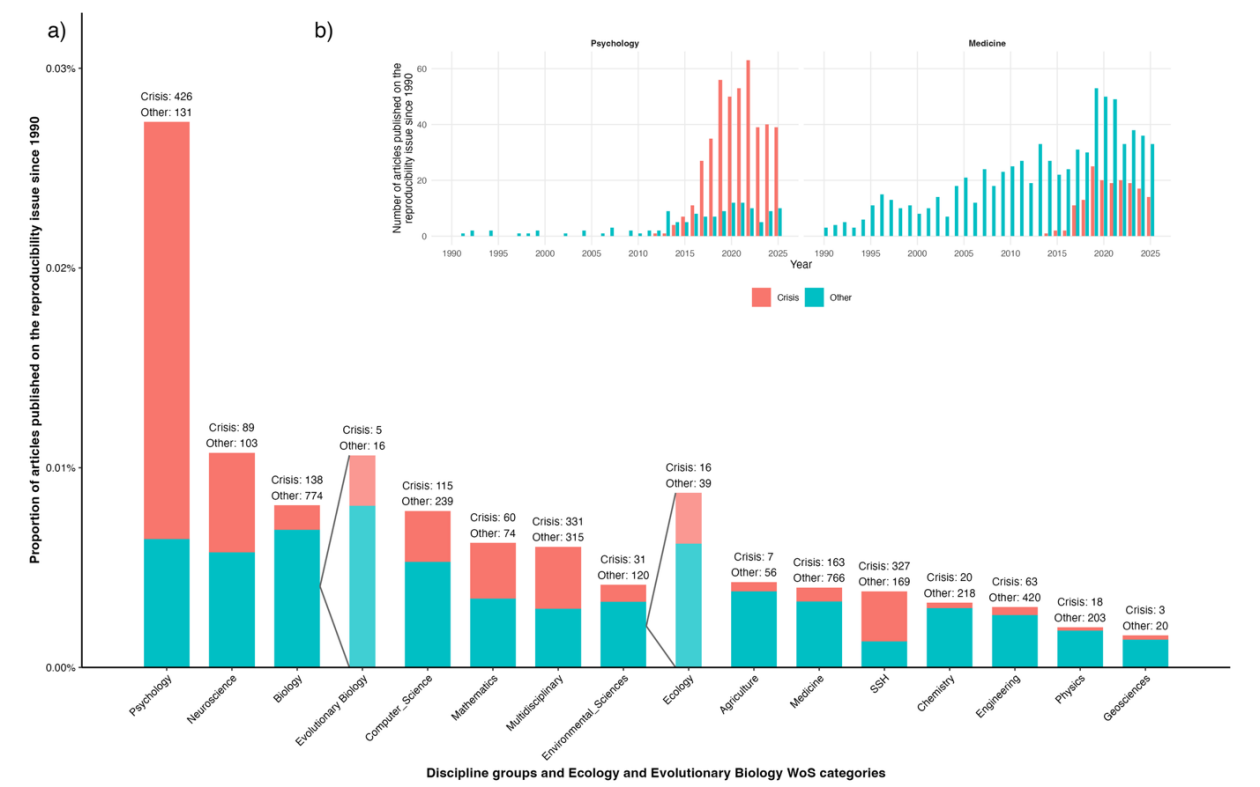
Figure 2. Articles published on the reproducibility issue across scientific disciplines. From Guillemaud and Bourguet’s Stage 1 Registered Report: Differences among disciplines in good scientific practices: requirements to justify sample size in psychology, medicine, agronomy, and ecology journals
One practical weakness: sample size justification
One of the most actionable insights from the webinar concerned sample size justification. In many fields, journals do not require authors to explain why their study includes a particular number of observations. Guillemaud and Bourguet analysed pilot data as part of a Stage 1 Registered Report, recommended by PCI Registered Reports (Lakens, 2026). heir analysis suggests that expectations vary widely across disciplines: medicine and psychology seem more likely to require justification, while ecology, evolutionary biology and agronomy seem to rarely do.
This matters because justifying sample size forces researchers to confront what their study can (and cannot) demonstrate. As emphasised during the Q&A, a priori power analysis — conducted before data collection — is one of the most informative tools for assessing whether a study design is capable of addressing its research question. By contrast, post hoc power calculations add little beyond what the p value already conveys and can be misleading.
Several audience questions touched on the real constraints researchers face: limited budgets, ethical considerations (for example, in animal research), or rare study populations. The speakers stressed that small sample sizes do not automatically invalidate a study — but they do limit the strength of the conclusions that can be drawn. Transparency is essential: researchers should justify their sample size, clearly state which effect sizes their study could plausibly detect, and avoid overinterpreting results from underpowered designs.
Shifting incentives with Registered Reports
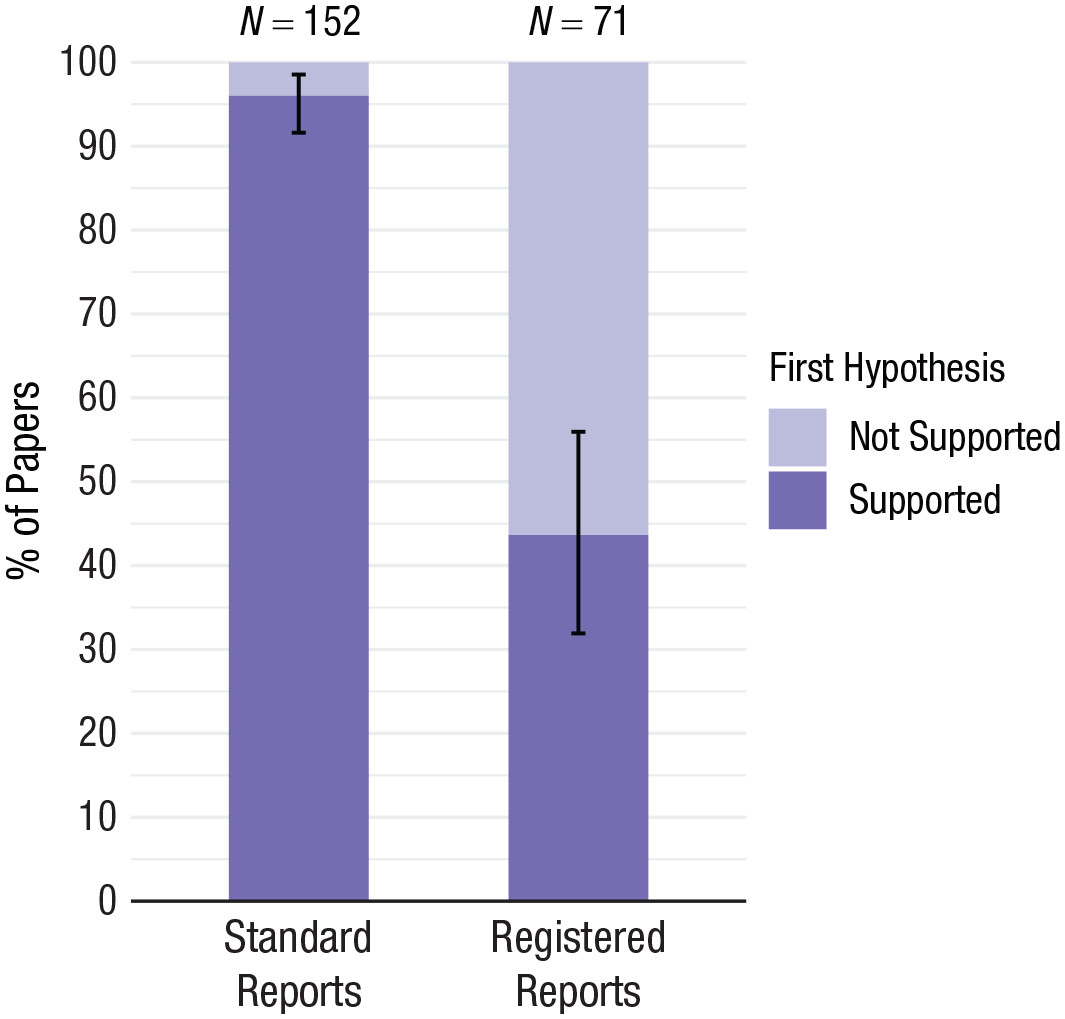
Figure 3. Positive result rates for standard reports and Registered Reports, from Scheel et al., 2021.
The reproducibility crisis is not just about individual mistakes; it is also about incentive structures. When publication decisions depend heavily on statistically significant, novel or “exciting” findings, researchers are nudged — consciously or not — toward practices that inflate false positives.
Registered Reports offer a structural alternative. In this publication model, study questions, hypotheses and methods are peer reviewed before data collection begins. If the design is evaluated as sound, the study receives in principle acceptance, and publication does not depend on how the results turn out. This change in evaluation criteria has a striking effect on the literature: research published in Registered Reports show a substantially lower proportion of positive findings when compared to conventional venues (40–60% vs. 80–95%). This does not indicate poorer research — it indicates more honest reporting (Scheel et al., 2021, Allen & Mehler, 2019; Warren, 2018).
Through PCI Registered Reports, this model operates within a non-commercial, community-driven framework that spans multiple disciplines, and allows studies to be evaluated primarily on methodological quality over outcome. If you would like to know more about Ghent University researchers’ experience with PCI registered reports, check out our blog post from our Preregistration & Coffee session.
Moving forward
The reproducibility crisis does not have a single cause or a single solution. But the way forward is clear: better aligned incentives, clearer justification of study designs, increased statistical literacy, and evaluation systems that prioritise rigor over significant results. These are not challenges that individual researchers can — or should — address in isolation.
Alongside supportive research policies, training and shared support play a crucial role. Doctoral schools offer courses on experimental design, specialist training such as FLAMES courses, and access to statistical consulting services provides practical support at key moments in the research process. Besides, communities are crucial: they shape norms, provide support and mutual learning opportunities, making robust research practices feasible in day‑to‑day work.
References and acknowledgements
-
Allen, C., & Mehler, D. M. A. (2019). Open science challenges, benefits and tips in early career and beyond. PLOS Biology, 17(5), e3000246.
https://doi.org/10.1371/journal.pbio.3000246 -
Begley, C. G., & Ellis, L. M. (2012). Raise standards for preclinical cancer research. Nature, 483(7391), 531–533.
https://doi.org/10.1038/483531a -
Building trust in scientific evidence. (n.d.). Retrieved April 10, 2026, from
https://www.nature.com/immersive/d42859-026-00015-y/index.html -
Button, K. S., Ioannidis, J. P. A., Mokrysz, C., Nosek, B. A., Flint, J., Robinson, E. S. J., & Munafò, M. R. (2013). Power failure: Why small sample size undermines the reliability of neuroscience. Nature Reviews Neuroscience, 14(5), 365–376.
https://doi.org/10.1038/nrn3475 -
Fanelli, D. (2010). “Positive” Results Increase Down the Hierarchy of the Sciences. PLoS ONE, 5(4), e10068.
https://doi.org/10.1371/journal.pone.0010068 -
Ioannidis, J. P. A. (2005). Why Most Published Research Findings Are False. PLoS Medicine, 2(8), e124.
https://doi.org/10.1371/journal.pmed.0020124 -
Ioannidis, J. P. A., Allison, D. B., Ball, C. A., Coulibaly, I., Cui, X., Culhane, A. C., Falchi, M., Furlanello, C., Game, L., Jurman, G., Mangion, J., Mehta, T., Nitzberg, M., Page, G. P., Petretto, E., & Van Noort, V. (2009). Repeatability of published microarray gene expression analyses. Nature Genetics, 41(2), 149–155.
https://doi.org/10.1038/ng.295 -
Jennions, M. D. (2003). A survey of the statistical power of research in behavioral ecology and animal behavior. Behavioral Ecology, 14(3), 438–445.
https://doi.org/10.1093/beheco/14.3.438 -
Lakens, D. (2022). Sample Size Justification. Collabra: Psychology, 8(1), 33267.
https://doi.org/10.1525/collabra.33267 -
Lakens, D. (2026). Examining Editorial Policies to Justify Sample Sizes Across Scientific Disciplines. Peer Community in Registered Reports.
https://rr.peercommunityin.org/articles/rec?id=1206 -
Lamberink, H. J., Otte, W. M., Sinke, M. R. T., Lakens, D., Glasziou, P. P., Tijdink, J. K., & Vinkers, C. H. (2018). Statistical power of clinical trials increased while effect size remained stable: An empirical analysis of 136,212 clinical trials between 1975 and 2014. Journal of Clinical Epidemiology, 102, 123–128.
https://doi.org/10.1016/j.jclinepi.2018.06.014 -
Reproducibility Project: Cancer Biology. (2014, December 10). eLife.
https://elifesciences.org/collections/9b1e83d1/reproducibility-project-cancer-biology -
Scheel, A. M., Schijen, M. R. M. J., & Lakens, D. (2021a). An Excess of Positive Results: Comparing the Standard Psychology Literature With Registered Reports. Advances in Methods and Practices in Psychological Science, 4(2), 25152459211007467.
https://doi.org/10.1177/25152459211007467 -
Scheel, A. M., Schijen, M. R. M. J., & Lakens, D. (2021b). An Excess of Positive Results: Comparing the Standard Psychology Literature With Registered Reports. Advances in Methods and Practices in Psychological Science, 4(2), 25152459211007467.
https://doi.org/10.1177/25152459211007467 -
Warren, M. (2018). First analysis of ‘pre-registered’ studies shows sharp rise in null findings. Nature.
https://doi.org/10.1038/d41586-018-07118-1 -
Yang, Y., Sánchez‑Tójar, A., O’Dea, R. E., Noble, D. W. A., Koricheva, J., Jennions, M. D., Parker, T. H., Lagisz, M., & Nakagawa, S. (2023). Publication bias impacts on effect size, statistical power, and magnitude (Type M) and sign (Type S) errors in ecology and evolutionary biology. BMC Biology, 21(1), 71.
https://doi.org/10.1186/s12915-022-01485-y
This blog post was written by the GhentCORR core team. Copilot was used for editorial support, including improving clarity, flow, and consistency of the text.
Enjoy Reading This Article?
Here are some more articles you might like to read next: